|
|
|
|
|
科学家提出基于化学微扰转录组自监督表征学习的药物筛选策略 |
|
|
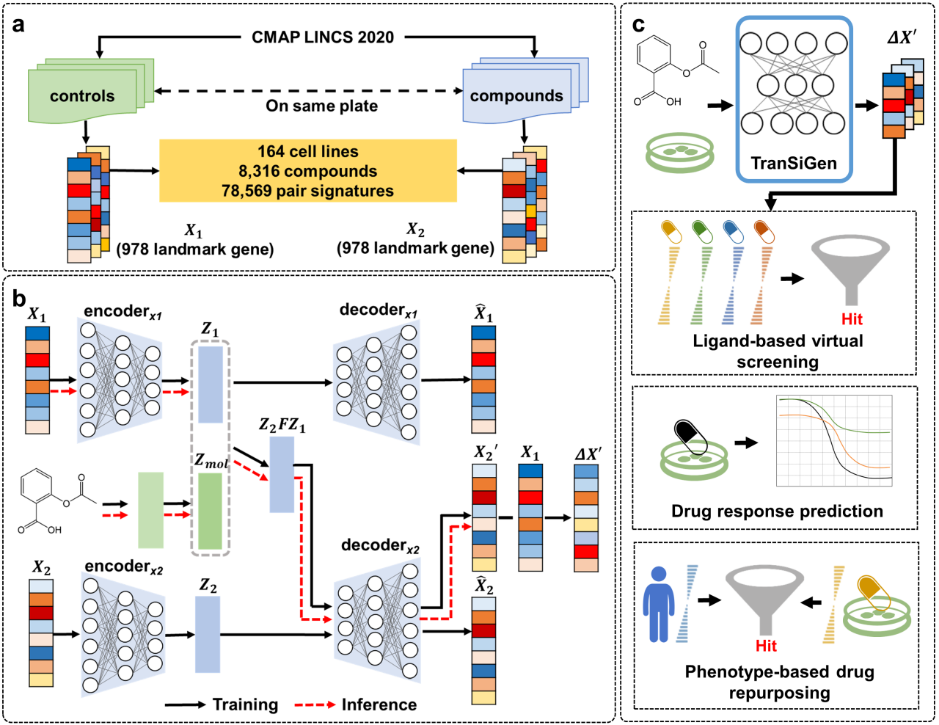
6月25日,中国科学院上海药物研究所研究员郑明月课题组提出基于自监督表征学习的深度生成模型TranSiGen,能够克服转录谱中固有噪声和混杂因素的局限,用于表征与细胞环境和化合物效应相关的表型信息,展现了其在药物发现中的应用前景。相关研究发表于《自然—通讯》。
基于表型的筛选是药物研发中的重要方法之一,通过全面评估化合物在细胞层面的响应,帮助人们更为深入地理解疾病机制,进而发现新的药物作用机制和潜在的治疗靶点。
高通量RNA测序技术的发展,促进了大规模微扰转录组的出现。以往研究中,科学家利用大量公共数据构建深度学习模型用于预测微扰转录组,但由于转录组数据中固有高噪声的存在,使得现有模型难以从中提取有意义的信息。
研究团队提出的TranSiGen模型,同时学习无扰动的本底谱、化学微扰转录谱以及它们之间的映射关系,利用自监督表征学习,有效减少了数据中的噪声,并揭示了其内潜在的扰动信号。广泛的评估表明,TranSiGen在推断本底谱、化学微扰转录谱以及相应的差异基因表达方面优于现有模型,且推断的差异基因表达可以有效地捕获细胞和化合物的特征。
在涉及药物发现的多种下游任务中,TranSiGen表征均表现出显著的有效性。进一步地,研究人员将TranSiGen用于抗胰腺癌活性化合物虚拟筛选,体外实验结果证实了其在药物筛选中的潜力。
TranSiGen架构和下游应用。图片来源于《自然—通讯》
相关论文信息:https://doi.org/10.1038/s41467-024-49620-3
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:
[email protected]。