|
|
|
|
|
FCS 文章精要:北京邮电大学傅湘玲教授团队等——用CB-Transformer学习从非对齐多模态序列中学习模态融合表征用于多模态情感识别 |
|
|
论文标题:LMR-CBT: learning modality-fused representations with CB-Transformer for multimodal emotion recognition from unaligned multimodal sequences
期刊:Frontiers of Computer Science
作者:Ziwang FU, Feng LIU, Qing XU, Xiangling FU, Jiayin QI
发表时间:28 Mar 2023
DOI: 10.1007/s11704-023-2444-y
微信链接:点击此处阅读微信文章
在多模态情感识别中,学习模态融合的表征和处理不一致的多模态序列是有意义的,也是具有挑战性的。现有的方法使用方向性的成对注意或信息枢纽来融合语言、视觉和音频模态。然而,这些融合方法相对于模态序列的长度来说往往是二次复杂的,带来了冗余的信息,而且效率不高。
为了解决上述局限性,北京邮电大学傅湘玲教授团队等撰写了研究论文:LMR-CBT:使用CB-Transformer学习从非对齐的多模态序列中学习。
文章信息
标 题:
LMR-CBT: learning modality-fused representations with CB-Transformer for multimodal emotion recognition from unaligned multimodal sequences
引用格式:
Ziwang FU, Feng LIU, Qing XU, Xiangling FU, Jiayin QI. LMR-CBT: learning modality-fused representations with CB-Transformer for multimodal emotion recognition from unaligned multimodal sequences. Front. Comput. Sci., 2024, 18(4): 184314
阅读原文:

文章概述
MulT只考虑了模态对之间的特征融合,忽略了三种模态的协调。此外,使用成对的方法来融合模态特征会产生冗余的信息。例如,在视觉-语言特征和视觉-音频特征的融合中,视觉表征会重复两次。PMR考虑了三种模态之间的关联,但通过设计一个集中的信息枢纽来融合模态特征会牺牲其效率。更具体地说,三种模式的信息需要与消息中心紧密地、递归地互动,以确保特征的完整性,而这样的操作需要大量的参数。最重要的是,现有的方法忽略了三种模式之间的信息强度差异,这导致在同一层融合不同密度的信息时产生噪音。也就是说,语言是一种人类产生的信号,具有高度的语义和信息密集性。相比之下,视觉和音频是具有大量空间冗余的自然信号,包含低级别的语义和单元特征。在音频和视觉两种模态的融合过程中,成对的跨模态变换器具有多模态序列长度的四维复杂性,这种操作是低效的。更重要的是,最近的方法由于预先训练过的模型,参数数量太高,无法适用于现实场景。
因此,为了解决上述局限性,我们提出了一个神经网络,通过CB-Transformer(LMR-CBT)学习模态融合表征,从未对齐的多模态序列中进行多模态情感识别。
技术步骤
具体来说,我们首先对三种模态分别进行特征提取,以获得序列的局部结构。对于音频和视觉模态,我们通过一维时间卷积获得相邻元素的信息。对于语言模态,我们使用双向长短时记忆(BiLSTM)来捕捉文本之间的长期依赖关系和上下文信息。在获得三种模态的特征表征后,我们设计了一个带有跨模态块的新型转化器(CB-Transformer)来实现不同模态的互补学习,主要分为局部时间学习、跨模态特征融合和全局自我注意表征。由于三种模态的信息差异,该模块是不对称的,即我们首先让视听模态通过Transformer进行模态特征的整合和选择,然后将增强的特征与文本交互,使得文本获得更有效的特征。在局部时间学习部分,我们发现音频和视觉输入包含密集的、细粒度的信息,其中大部分是冗余的。因此,音频和视觉特征被用来通过变换器获得两个模态的相邻元素相关的表示。在跨模态特征融合部分,基于残差的模态交互方法被用来获得三种模态的融合特征。在全局自我注意表征部分,转化器在融合模态中学习高级表征。CB-Transformer可以充分表示融合后的特征而不丢失原始特征,并能有效地处理不对齐的多模态序列。最后,我们将模态融合特征与原始特征进行拼接,得到情感类别。
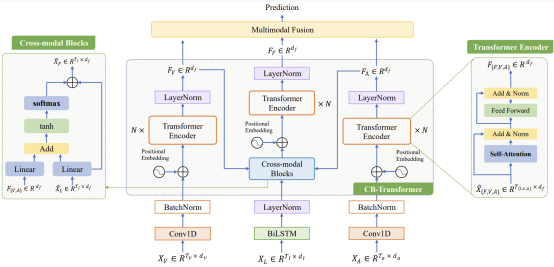
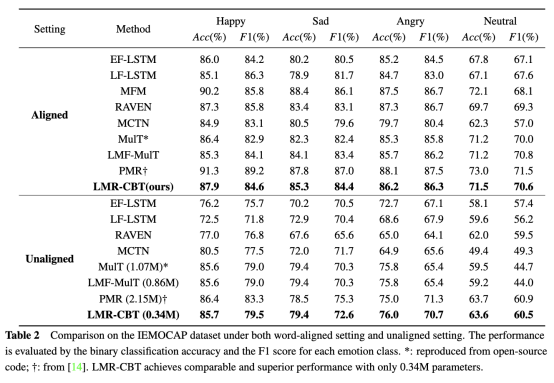
实验结果
我们在三个主流的多模态情感识别公共数据集上进行了词对齐和不对齐的实验,即IEMOCAP、CMU-MOSI和CMU-MOSEI。实验结果证明了我们提出的方法的优越性。此外,我们在性能和效率之间实现了更好的权衡。与主流方法相比,我们的方法以最小的参数数量达到了最先进的水平。


相关内容推荐:
文章精要 | 苏州大学李培峰教授团队:结合上下文证据改进汉语隐式篇章关系识别 2024 18(3):183312
文章精要 | 中山大学刘玉葆教授团队:基于自适应特定映射的无监督社交网络嵌入 2024 18(3):183310
文章精要 | 重庆邮电大学张清华教授团队:一种基于多关系和多路径的不确定性知识图谱嵌入方法 2024 18(3):183311
文章精要 | 哈尔滨工程大学於志文教授团队等:EvolveKG: 一种演化知识图谱通用学习框架 2024 18(3):183309
文章精要 | 北京师范大学段福庆教授团队:基于小波散射变换的混合域人脸属性估计研究 2024 18(3):183313
文章精要 | 国防科技大学侯臣平教授团队:弱标签先验约束聚类 2024 18(3):183338
文章精要 | 广州大学刘文斌教授团队:FedDAA:一种鲁棒联邦学习框架用于保护隐私和防御对抗攻击 2024 18(2):182307
文章精要 | 广东技术师范大学张越副教授团队:基于张量显著共峰搜索的弱监督实例共分割 2024 18(2):182305
文章精要 | 武汉大学肖春霞教授团队:CRD-CGAN: 基于类型一致性和相对性约束的多样性文本生成图象 2024 18(1):181304
文章精要 | 用于常识问答的基于知识图谱的元路径推理 2024 18(1):181303
文章精要 | 双曲数据分类器的核化研究 2024 18(1):181301
文章精要 | 联邦学习综述:多方计算的视角 2024 18(1):181336

Frontiers of Computer Science
Frontiers of Computer Science (FCS)是由教育部主管、高等教育出版社和北京航空航天大学共同主办、SpringerNature 公司海外发行的英文学术期刊。本刊于 2007 年创刊,双月刊,全球发行。主要刊登计算机科学领域具有创新性的综述论文、研究论文等。本刊主编为周志华教授,共同主编为熊璋教授。编委会及青年 AE 团队由国内外知名学者及优秀青年学者组成。本刊被 SCI、Ei、DBLP、INSPEC、SCOPUS 和中国科学引文数据库(CSCD)核心库等收录,为 CCF 推荐期刊;两次入选“中国科技期刊国际影响力提升计划”;入选“第4届中国国际化精品科技期刊”;入选“中国科技期刊卓越行动计划项目”。
《前沿》系列英文学术期刊
由教育部主管、高等教育出版社主办的《前沿》(Frontiers)系列英文学术期刊,于2006年正式创刊,以网络版和印刷版向全球发行。系列期刊包括基础科学、生命科学、工程技术和人文社会科学四个主题,是我国覆盖学科最广泛的英文学术期刊群,其中12种被SCI收录,其他也被A&HCI、Ei、MEDLINE或相应学科国际权威检索系统收录,具有一定的国际学术影响力。系列期刊采用在线优先出版方式,保证文章以最快速度发表。
中国学术前沿期刊网
http://journal.hep.com.cn

特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






